


A bit Semantic Segmentation
When it comes to semantic segmentation, the first question to ask yourself is do you need it real-time? While plenty of solutions have been around with decent results for this problem, the more recent research has been about achieving better results in real-time. They call it speed vs accuracy tradeoff.
A solution like remove(.bg), which removes background from an uploaded image, seems relatively easier compared to the needs of an autonomous car. More trickier is to work with weak hardware like raspberry pi or even cell phones.
So why not just throw a convolutional net at it? Yes you could, but what made object detectors perfect now comes back to haunt you.
It's the pooling layer.
Pooling layer plays a key role in Convolutional Neural Nets (CNNs) by reducing dimensionality and adding a wider view for object detection. Max pooling (shown below) is the most effective method as shown by LeCun et all
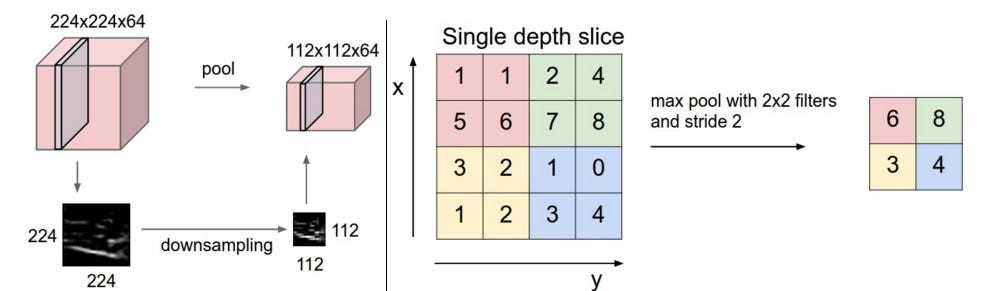
Consider the below pictures of a human sperm. In this case, the only pixel location that we would care about is the one with tip of the sperm. A function like max pooling enables this for us. Irrespective of the location of tip, we derive the pixel value that holds most important information in this grid.

On the downside, the pooling layer does cause loss of positional information (as you can see in the image above). And when it comes to segmentation, we are interested in exact pixel in the image that makes up the object.
Some architectures handle this through upsampling (u-net), while others like well known DeepLab uses atrous or dilated kernel. This type of convolution seems to increase the field of view looked at by convolution layers and you could have similar effect as max-pooling. Deep lab also seems to use varying dilation size which makes network go through to image pyramids going from coarse to fine features
State of the art architectures for semantic segmentation:
Mask RCNN
u-net (famous for medical images due to spatial precision)
Deep Lab v1-3
Yolo v1-3
SSD
Fast rCNN
Faster RCNN